실제 데이터셋은 분석에 바로 투입되기엔 난해할 가능성이 큽니다. 이러한 난해한 데이터들은 크게 결측치(Missing Value)와 이상치로 분류할 수 있으며, 이를 잘처리하는 것이 분석 결과를 좌우할 수 있다고 할 수 있습니다. 해당 포스트에서는 결측치가 무엇인지, 어떻게 처리해야 좋을지에 대해 말씀 드리겠습니다.
27.1. 결측치 정의와 생성하기
(1) 결측치의 정의
결측치란 데이터에서 값이 누락되어 아무런 의미를 가지지 않는 값을 의미합니다. 주로 R에서는 NA라는 값으로 명시되거나, 제공처에서 임의로 명시한 값(예: 9999, "unknown", ... )으로 처리되어 있습니다.
(2) 결측치의 유형
결측치는 분석 결과에 영향을 주느냐, 주지 않느냐에 따라 크게 3가지로 구분할 수 있습니다. 이를 표로 정리하면 다음과 같습니다.
| 형태 | 설명 |
| 완전무작위결측 (MCAR : Missing Completely At Random) |
다른 변수와 무관하게 랜덤으로 발생한 결측치 |
| 무작위결측 (MAR : Missing At Random) |
결측이 다른 변수와 연관이 있으나, 그 자체가 데이터 분포에 영향을 미치지는 않는 결측치 |
| 비무작위결측 (NMAR : Not Missing At Random) |
결측값이 데이터 분포에 영향을 미치는 결측치 |
쉽게 구분하고자, 남녀성비에 따른 임금격차를 주제로 하는 연구에서 데이터를 수집하고자 설문조사할 때를 예시로 들겠습니다.
①완전무작위결측(MCAR): 성별, 나이 같은 변수와 무관하게 대답을 하지 않는 경우, 혹은 일부는 대답하고 일부는 안하는 등의 고의성 없이 응답이 빠뜨린 경우
②무작위결측(MAR): 성별에 따라 결측치가 남성 혹은 여성 비율이 더 높을 수 있지만, 데이터의 분포에는 영향을 미치지 않음
③비무작위결측(NMAR): 임금이 낮은 사람은 설문조사에 응답할 확률이 낮음
(3) 결측치 생성 방법
결측치는 데이터셋을 탐색할 때 발견되기도 하지만, 거꾸로 전처리를 위해 특정값들을 결측치로 처리할 때도 있습니다. 결측치를 생성할 때는 "NA"라는 입력을 통해 할당됩니다. 대소문자를 구분하니 유의하는게 좋습니다. 예를 들어 vector_01을 정의하면 다음과 같습니다.
vector_01 <- c(1, 2, 3, 4, 5)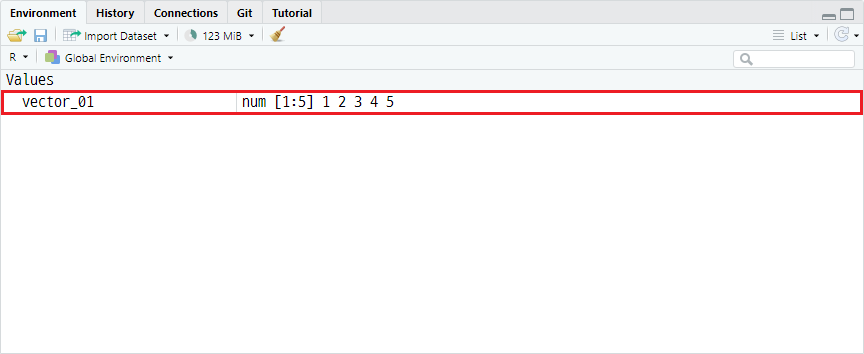
vector_01의 세 번째 원소를 결측값으로 변환하고자 할 경우, 코드는 다음과 같습니다.
vector_01[3] <- NA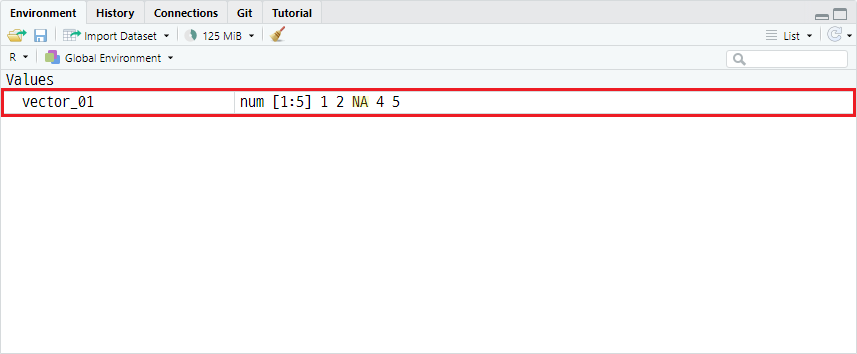
27.2. 결측치 파악하기
결측치를 파악하기 전 머신러닝용 연습 데이터셋인 titanic 데이터셋을 예시로 들겠습니다. titanic 데이터셋은 생존자를 분류하기 위한 대표적인 데이터셋으로, 자세한 설명은 <2019 1st ML month With KaKR>에서 참고하세요. titanic 데이터셋 중 훈련(Train) 데이터셋을 호출하는 과정은 다음과 같습니다.
titanic_train <- read.csv("Data/2019_1st_ML_month_with_KaKR/train.csv")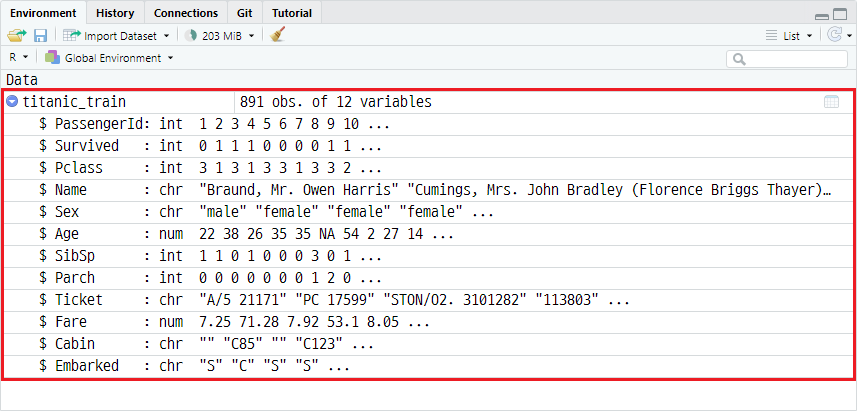
(1) 결측치 파악 함수, is.na()
is.na() 함수는 객체의 원소가 결측치인지 논리형으로 반환하는 함수입니다. 단독으로 사용하기엔 시안성에 문제가 있어, 주로 colSums() 함수와 함께 사용합니다. titanic_train에서 결측치가 몇 개 있는지 파악하고자한다면 코드는 다음과 같습니다.
is.na(titanic_train)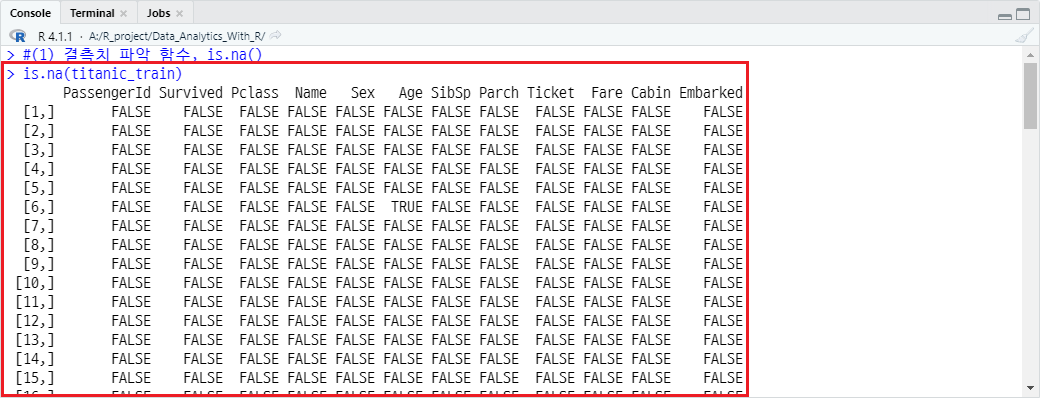
보시는 바와 같이, 각 원소에 대해 매칭된 논리형을 반환하기 때문에 한 눈에 파악하기 어렵습니다.
(2) colSums() 함수와 결합한 이상치 파악
colSums() 함수는 열을 기준으로 값들을 합하는 함수입니다. is.na() 함수와 결합하여 사용하면, 어느 열에 결측치가 몇 개가 존재하는지 쉽게 파악할 수 있습니다.
colSums(is.na(titanic_train))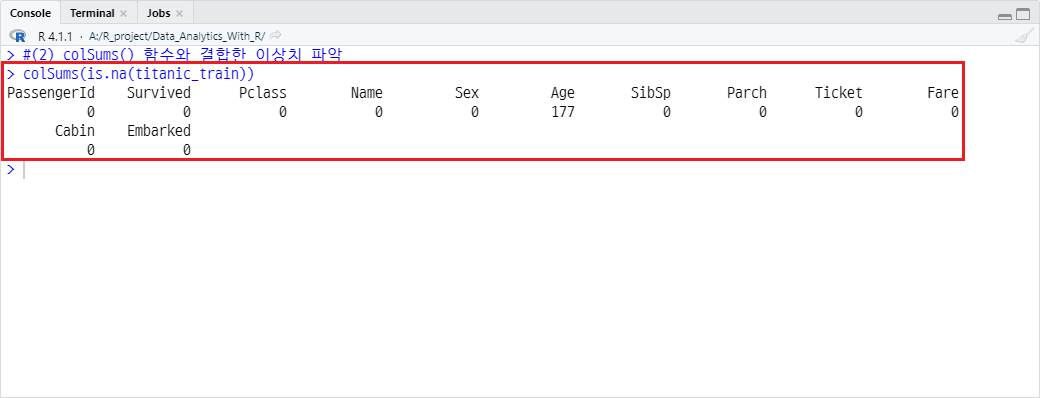
27.3. 결측치 처리하기
(1) 행기준 결측치 제거, na.omit()
na.omit() 함수를 이용한다면, 데이터셋에 결측치가 존재하는 행(표본)을 제거할 수 있습니다. 아주 간단한 방법이나 데이터셋의 행 수가 적어진다는 단점이 있습니다. titanic_train에서 존재하는 결측값 177개를 제거하여 새로운 객체 titanic_train_rmna에 할당하고자한다면 다음과 같습니다.
titanic_train_rmna <- na.omit(titanic_train)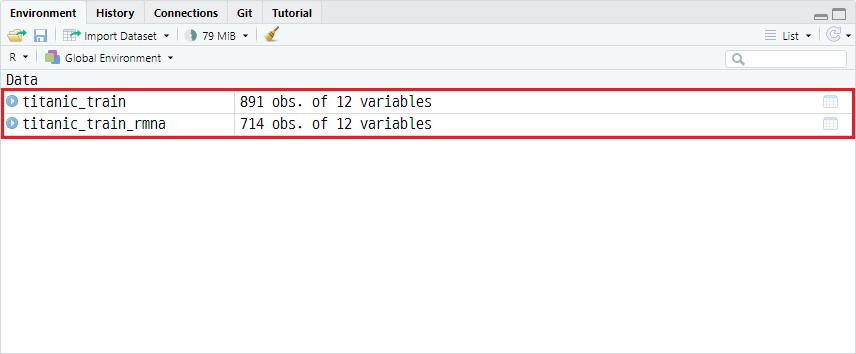
titanic_train_rmna는 177개가 제거된 714개의 표본을 가짐을 확인할 수 있습니다.
PLUS) 기본 산술 함수에서 na.rm 파라미터 사용하기
<11. R의 기본 산술 함수 파악하기>에서 우리는 R에서 제공되는 기본 산술 함수를 배웠었는데, 계산하는 데이터셋에 결측치가 존재할 경우 아래와 같이 NA로 반환합니다.
mean(titanic_train$Age)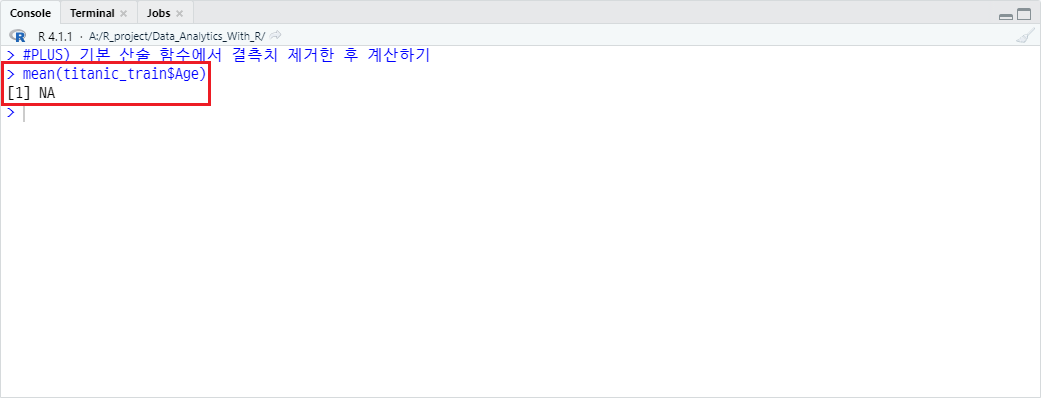
단, na.rm=TRUE 파라미터를 사용할 경우, 해당 결측치를 제거하여 계산함을 확인할 수 있습니다.
mean(titanic_train$Age, na.rm = TRUE)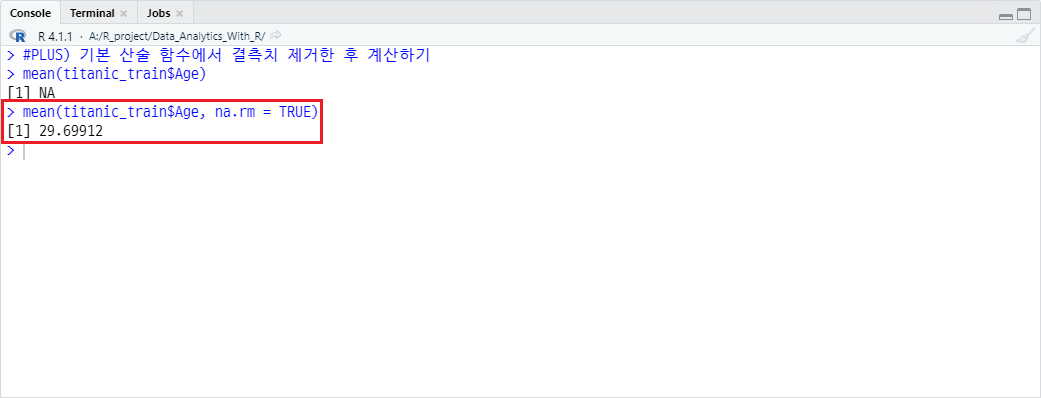
(2) 결측치 대체
결측치를 대체하는 방법은 크게 3가지로 분류할 수 있습니다.
①통계적 수치(평균, 최빈, ... )의 값으로 대체
②머신러닝 기법(군집화, ... )을 이용하여 대체
③도메인 지식에 근거하여 대체
해당 포스트에서는 기본적으로 통계값들로 결측치를 대체하는 방법을 알아보겠습니다. titanic_train에서 age열의 결측치들을 평균으로 대체하고자 하면, ifelse() 함수를 이용하여 간단하게 대체할 수 있습니다.
titanic_train$Age <- ifelse(is.na(titanic_train$Age),
mean(titanic_train$Age, na.rm=TRUE),
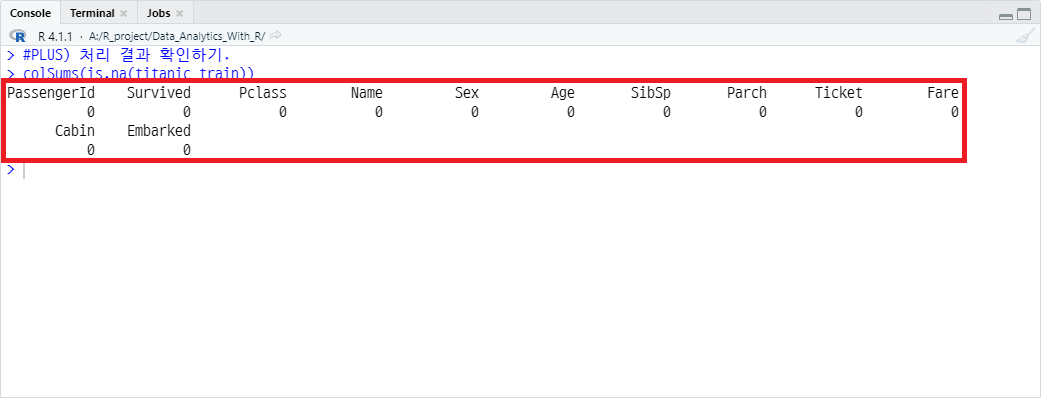
titanic_train$Age)이후 처리 결과를 확인하면 다음과 같이 결측값이 없음을 확인할 수 있습니다.
'Ⅱ. 데이터 전처리 > ⅰ. Base 문법' 카테고리의 다른 글
| 30. 이상치 판단 및 전처리하기 (수정중) (0) | 2021.06.01 |
|---|---|
| 29. 중복값 파악 및 처리하기 (작성중) (0) | 2021.05.31 |
| 27. 데이터프레임 결합하기 (작성중) (0) | 2021.05.26 |
| 26. 데이터프레임 그룹핑하기 (작성중) (0) | 2021.05.24 |