결측치 처리와 마찬가지로, 데이터셋에서 이상치(Outlier)를 파단하고 처리하는 것 역시 중요합니다. 이상치는 결측치와 성격이 비슷해보이나, 이를 처리하기엔 좀 더 많은 도메인 지식과 표본 수집 배경을 파악하는 것이 요구됩니다. 해당 포스트에서는 주로 어떤 방법으로 이상치들을 전처리하는지 소개하겠습니다.
29.1. 이상치 정의와 판단하기
(1) 이상치 정의
이상치란 관측된 데이터셋의 일반적인 범위에서 벗어난 아주 작은 값이나 아주 큰 값을 의미합니다. 데이터 수집시 실수로, 혹은 측정 단위나 데이터 오류로 발생할 수 있습니다.
(2) 이상치 판단
이상치를 파단하기란 결측치보다 더 까다로운 편입니다. 무엇보다 이상치를 판단하는 과정은 분석가의 합리적인 주관과 근거가 요구되기 때문입니다. 또한 파악할 때도 결측값은 특정한 지점(point)만을 확인한다면, 이상치는 데이터셋의 전반적인 흐름을 파악해야하기 때문입니다. 이상치를 판단하는 방법은 크게 4가지가 있는데 그 방법은 아래와 같습니다.
①도메인 지식에 근거하여 판단
②시각화를 통해 판단
③일반적인 통계적 방법(Boxplot, 3-sigma-rule, ... )을 이용
④머신러닝 기법을 이용해 판단(K-NN, Clustering, ... )을 이용
(3) 예시
위의 ②번에서 도메인 지식에 근거하여 판단하는 게 어떤 의미인지 예를 들어 보겠습니다. 어떠한 학교에서 5명의 학생의 성별, 키(cm), 체중(kg) 정보를 기록한 데이터 프레임을 정의하겠습니다.
student_info <- data.frame(
name = c('PSH', 'CGE', 'CSH', 'CMJ', 'CJH'),
gender = factor(c('m', 'f', 'm', 'f', 'm')),
height = c(177, 160, 176, 159, 172),
weight = c(75, 46, 71, 380, 22.5)
)
이상치를 파악하기 위해선 데이터를 탐색해야하는데, 우리는 이전에 배운 <17. 데이터셋 탐색하기>에서 여러 탐색 함수들을 배웠습니다. 허나 위의 데이터셋은 소규모로 이루어져 있으므로, View() 함수를 통해 간단하게 판단하겠습니다.

해당 데이터셋을 살펴보면, 4번 관측치에서 키가 159cm인 반면 몸무게는 380kg임을 알 수 있습니다. 5번 관측치에서도 키가 172cm인데 몸무게는 22.5kg인데, 이는 물리적으로 불가능함을 알 수 있습니다. 우리는 이러한 도메인 지식에 근거하여 4번과 5번은 이상치로 정의할 수 있습니다.
29.2.이상치 처리하기
이번에는 ggplot2 패키지의 mpg(mile per gallon) 패키지를 이용하여 이상치를 판단 후 처리하는 방법을 말씀드리겠습니다. mpg 데이터셋이란, 미국 환경 보호국에서 공개한 자료로, 1999~2008년 사이 미국에서 출시된 자동차 중 가장 인기가 많은 38종의 cty(도로주행연비), hwy(고속도로주행연비) 정보를 포함하고 있습니다. 해당 데이터셋을 호출하는 방법은 다음과 같습니다.
mpg_raw <- as.data.frame(ggplot2::mpg)
mpg <- mpg_raw #BACK-UP
컬럼(변수)의 자세한 의미는 <Rdocuments의 게시글>에서 확인하세요.
(1) Boxplot() 함수를 이용한 이상치 제거
Boxplot이란, 데이터의 대략적인 분포와 사분위수범위(InterQuartile Range; IQR)을 이용해서 개별적인 이상치들을 동시에 보여줄 수 있는 그래프입니다. Boxplot에 대한 자세한 내용은 <link>에서 설명하겠습니다. mpg 데이터셋의 hwy에서 이상치를 판별하고자 할 때, boxplot() 함수의 속성인 stats를 이용하여 이상치를 식별하면 다음과 같습니다.
boxplot(mpg$hwy)$stats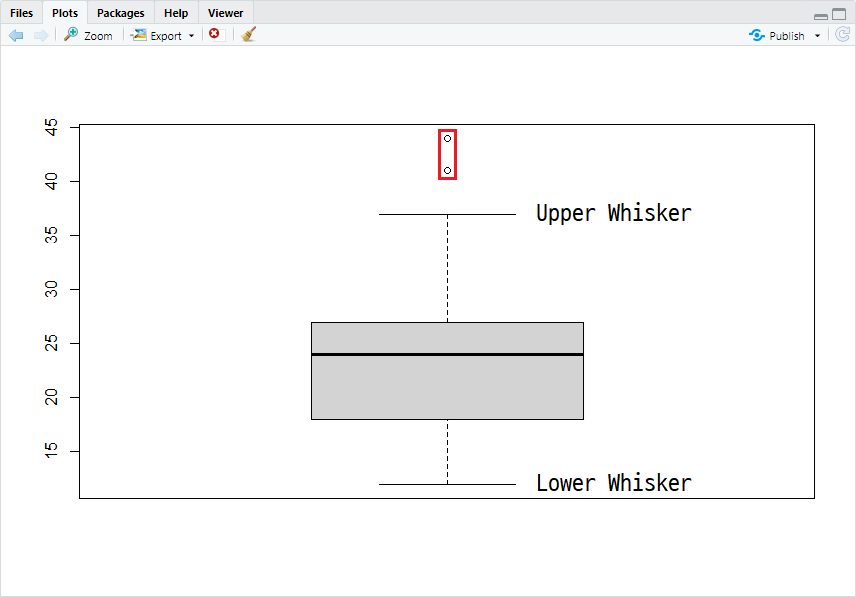

시각화 및 출력 결과를 요약하자면, mpg 데이터셋의 hwy 컬럼에서 2개의 이상치 point가 식별됐으며, 이 두 point는 boxplot의 Upper Whisker, 37보다 큼을 확인할 수 있습니다. 해당 이상치를 처리하는 방법은 ifelse() 함수를 이용하여 처리할 수 있습니다. 처리 결과를 확인하면 다음과 같습니다.
mpg$hwy <- ifelse(mpg$hwy > 37, NA, mpg$hwy)
table(is.na(mpg$hwy)) #결측값 갯수 파악
결측치로 처리된 값이 2개가 아니라 3개임을 확인할 수 있는데, 사실 boxplot에서 한 point에 2개의 행(중복값)이 있었음을 확인할 수 있습니다. 이는 필터링을 통해 확인할 수 있으니 생략하겠습니다. 처리 결과를 다시 확인하기 위해 boxplot()을 다시 출력하면 다음과 같습니다.
boxplot(mpg$hwy)$stats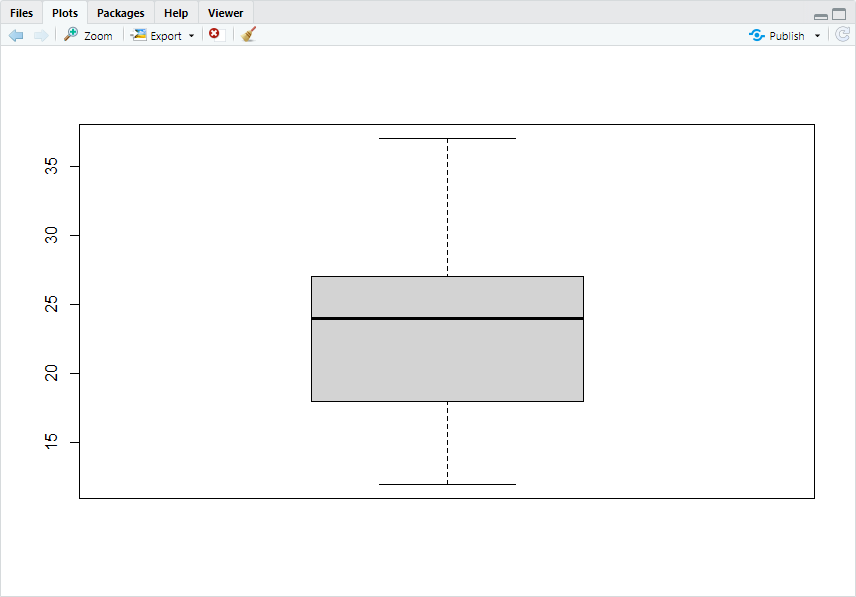
(2) 3-sigma-rule을 이용한 이상치 제거 = Extreme Studentized Deviate test
3-sigma-rule이란 수집한 데이터셋의 모집단이 정규분포일 때, 평균 양측(+, -)으로부터 3표준편차(σ; sigma) 범위에 거의 모든 값(99.7%)이 포함됨을 의미합니다. 아래는 표준정규분포에서 표준편차의 범위에 따라 데이터의 포함 비중을 표시한 그래프입니다.
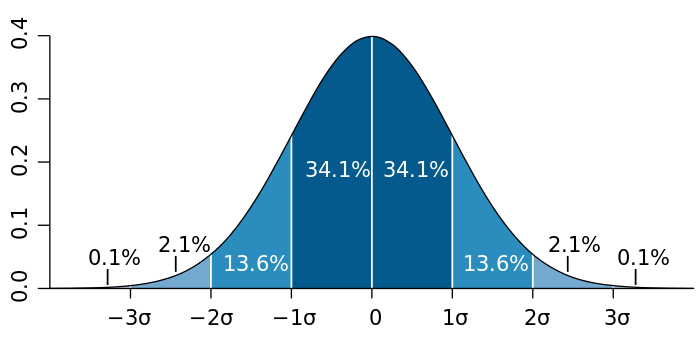
출처: https://ko.wikipedia.org/wiki/68-95-99.7_%EA%B7%9C%EC%B9%99
1표준편차 범위에서는 전체 데이터의 약 68%를, 2표준편차 범위에서는 95%를, 3표준편차 범위에서는 99%를 포함함을 확인할 수 있습니다. 단순하고 직관적인 이상치 처리 방법으로써, 3표준편차보다는 2표준편차 사용하는 것이 일반적으로 많이 알려져 있습니다. 왜냐하면 정규분포에서 3표준편차의 범위를 적용했을 때, 나머지 1%가 이상치로 정의되는 것은 너무 적기 때문입니다.
3-sigma-rule을 이용해 이상치를 처리하는 방법은 다음과 같습니다. 위의 방법과 마찬가지로 ifelse() 함수를 이용하여 처리할 수 있습니다.
mean_hwy <- mean(mpg$hwy)
sigma_hwy <- sd(mpg$hwy)
mpg$hwy <- ifelse(mpg$hwy > mean_hwy + 3 * sigma_hwy | mpg$hwy < mean_hwy - 3 * sigma_hwy,
NA,
mpg$hwy)
table(is.na(mpg$hwy))
처리 결과를 확인해보면, 2개의 값이 이상치로써 결측처리 됐음을 확인할 수 있습니다.
'Ⅱ. 데이터 전처리 > ⅰ. Base 문법' 카테고리의 다른 글
| 32. 텍스트 데이터 전처리하기 (작성중) (0) | 2021.06.11 |
|---|---|
| 31. 시계열 데이터 전처리하기 (수정중) (0) | 2021.06.08 |
| 29. 중복값 파악 및 처리하기 (작성중) (0) | 2021.05.31 |
| 28. 결측값 생성, 파악 및 처리하기 (수정중) (0) | 2021.05.28 |