(서론)
26.1. ㅇㅇ
───
레거시 자료
───
데이터셋의 값 혹은 구조를 변경하는 것 외에도, 데이터셋의 성질을 파악하는 것 역시 데이터 전처리 과정입니다. 성질을 파악하기 위해선 통계적으로 접근하거나, 데이터셋을 묶거나 세부 분류를 다시 확인하는 방법이 있습니다. 이번 포스트에서는 aggregate(), table() 함수 외에도 기타 전처리 함수를 이용해 데이터셋의 성질을 파악하는 과정을 살펴보겠습니다.
26.1. 인덱싱 함수, which()
(1) which() 함수의 구조
which() 함수는 데이터셋의 특정 조건을 만족하는 값들의 인덱스를 반환하는 함수입니다. 함수의 구조는 다음과 같습니다.
| which(x, arr.ind, ∙∙∙) |
| 파라미터 | 설명 |
| x | 입력값(데이터셋) |
| arr.ind | 입력값이 행렬이나 배열일 경우, 행∙열 인덱스로 반환 |
arr.ind 파라미터는 아래의 예시를 통해 설명하겠습니다.
(2) 예시
예시를 위해 원소 1, 4, 2, 3, 5를 가지는 vector_01 객체를 정의하겠습니다.
vector_01 <- c(1, 4, 2, 3, 5)
vector_01 중 값이 4인 원소의 인덱스를 찾고자 할 때, 코드는 다음과 같습니다.
which(vector_01==4)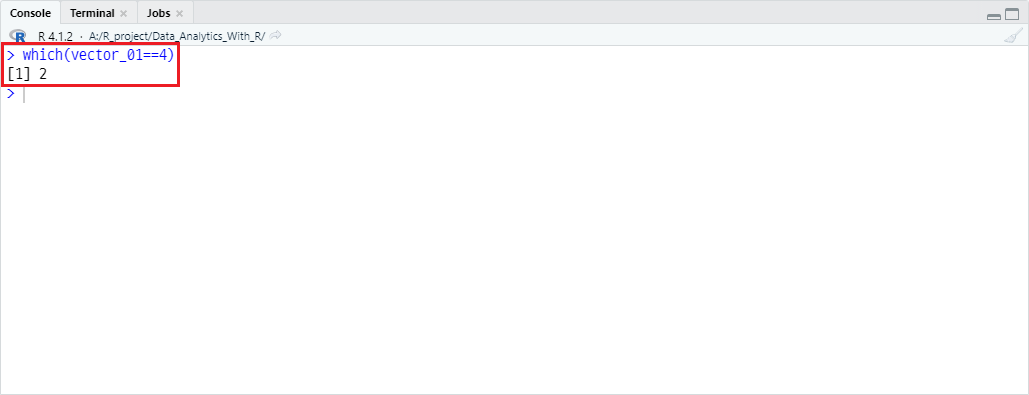
(3) arr.ind 파라미터를 활용한 예시
예시를 위해 matrix_01 객체를 정의하겠습니다.
matrix_01 <- matrix(data = c(1, 2, 3, 4, 5, 6, 7, 8, 9),
nrow = 3,
ncol = 3,
byrow = TRUE)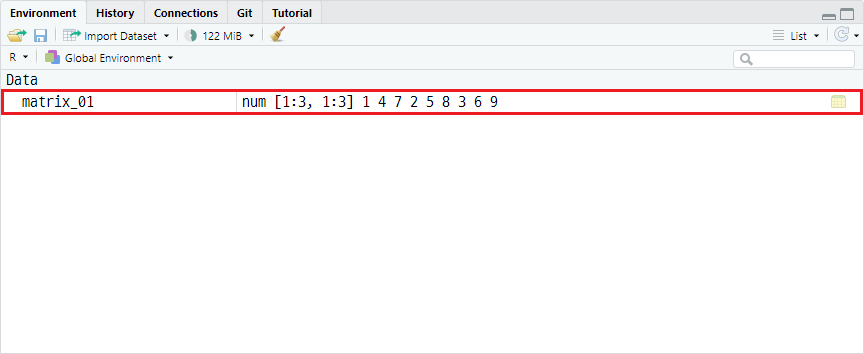
matrix_01 객체 중 값이 7인 원소의 인덱스를 찾고자 할 때, 코드는 다음과 같습니다.
which(matrix_01==7)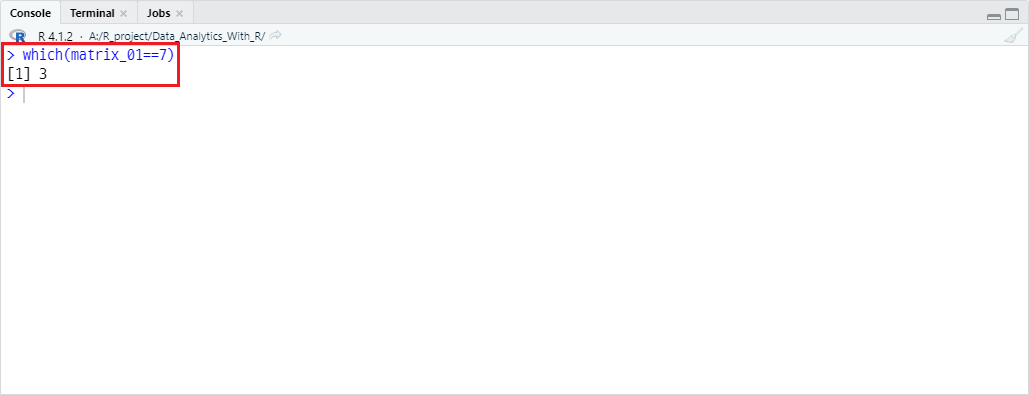
반환값은 3인데, R은 기본적으로 열을 기준으로 index를 설정하기 때문입니다. 여기서 arr.ind 파라미터를 TRUE로 설정할 시의 결과는 다음과 같습니다.
which(matrix_01==7, arr.ind=TRUE)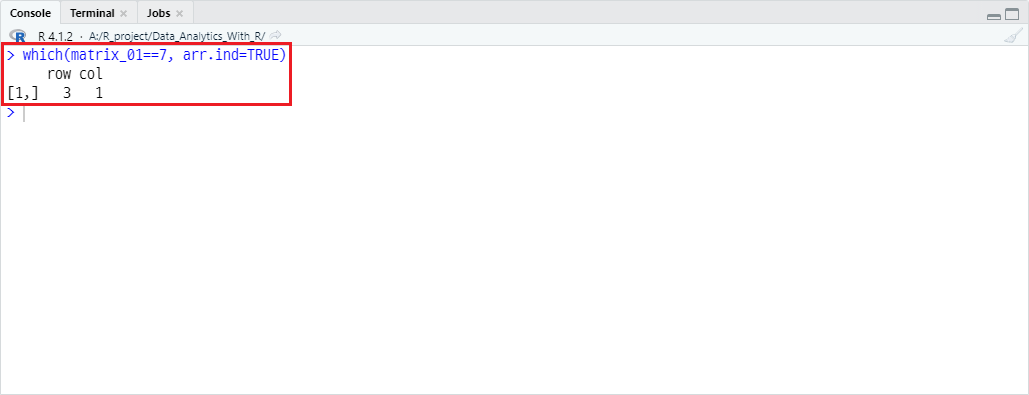
반환 결과 3행 1열로 출력함을 확인할 수 있습니다.
26.2. 그룹핑 함수, aggregate()
(1) aggregate() 함수의 구조
aggregate() 함수는 데이터셋을 특정 기준으로 그룹핑(Grouping)해 요약하는 함수입니다. 그룹핑이란 특정 값(집단)을 기준으로 묶어 다시 분류하는 것을 의미하는데, 함수의 구조는 다음과 같습니다.
| aggregate(formular, data, FUN, ∙∙∙ ) |
| 파라미터 | 설명 |
| formular | '(함수)적용열~기준열' 형식으로 정의 |
| data | 입력값(데이터셋) |
| FUN | 적용열에 작동할 함수 정의 |
(2) formular 형식의 이해
formular 형식이란, 두 변수간의 관계를 ~(Tilde Sign)을 통해 표현하여 정의하는 것을 의미합니다. 주로 여러 통계, 머신러닝 등 데이터 분석용 함수에서 사용되며, aggregate() 함수의 formular 사용 방법은 다음과 같이 사용됩니다.
예시를 위해 이전 포스트인 <24. 데이터셋 결합하기>에서 1반, 2반 학생의 정보를 결합한 student_dataset을 다시 사용하는 과정은 다음과 같습니다.
student_dataset <- read.csv('a:/R_project/Data_Analytics_With_R/Data/student_dataset.csv')
반 번호(class_num)을 기준으로, 국어 점수(korean)의 평균을 그룹핑하고자 하는 과정은 다음과 같습니다. 먼저 해당 변수들의 관계를 빨간, 파란색 박스를 통해 확인하면 다음과 같습니다.

이러한 관계를 formular로 표현하자면 다음과 같습니다.

(3) 예시
위의 예시를 기준으로 aggregate() 함수를 사용하는 코드는 다음과 같습니다.
aggregate(korean~class_num, student_dataset, mean)
26.3. 벡터 정렬 함수, sort()∙order()
(1) 값 정렬 함수, sort()
sort() 함수는 벡터 구조의 원소들의 값을 정렬하는 함수입니다. decreasing 파라미터를 통해 내림차순처리할 수 있습니다. 예를 들어 student_dataset의 수학점수를 기준으로 내림차순 정렬하고자 할 경우 다음과 같습니다.
sort(student_dataset$math, decreasing = TRUE)
(2) 인덱스 기반 정렬 함수, order()
order() 함수는 sort() 함수와 비슷하지만, 값이 아닌 인덱스를 반환하는 함수입니다. 위의 예시와 동일하게 수학점수를 기준으로 내림차순한 인덱스를 확인하고자할 경우 다음과 같습니다.
order(student_dataset$math, decreasing = TRUE)
(3) order() 함수를 이용한 데이터셋 정렬
order() 함수의 주로 인덱싱을 이용하여 데이터셋을 정렬하고자할 때 사용합니다. 사용 방법은 아래와 같은데, 수학점수를 기준으로 내림차순한 데이터셋을 반환하고자 할 경우 다음과 같습니다.
student_dataset[order(student_dataset$math, decreasing = TRUE), ]
26.4. 행∙열 단위 처리 함수, apply() (수정중)
(1) apply() 함수의 필요성
R은 형편없는 구동 속도로 악명이 높습니다. 특히 이중 반복문을 시행할 시 그 속도가 어마하게 느려지는데, 이를 어느정도 해소하기 위해 apply() 함수를 사용합니다. 이는 특히 빅데이터를 처리하는데 적합합니다.
(2) apply() 함수의 구조
apply() 함수는 행∙열 단위로 함수를 적용해 처리하는 함수입니다. 함수의 구조는 다음과 같습니다.
| apply(X, MARGIN, FUN, ∙∙∙ ) |
| 파라미터 | 설명 |
| X | 입력값(데이터셋) |
| MARGIN | 1이면 행, 2면 열 기준으로 적용 |
| FUN | 적용열에 작동할 함수 정의 |
(3) 예시
위의 matrix_01 객체에서 행 기준으로 모두 더하고자 할 경우, 코드는 다음과 같습니다.
apply(X=matrix_01, MARGIN=1, FUN=sum)
반대로 열 기준으로 모두 더하고자 할 경우, 코드는 다음과 같습니다.
apply(X=matrix_01, MARGIN=2, FUN=sum)
PLUS) lapply(), sapply() 함수
(내용 추가)
'Ⅱ. 데이터 전처리 > ⅰ. Base 문법' 카테고리의 다른 글
| 28. 결측값 생성, 파악 및 처리하기 (수정중) (0) | 2021.05.28 |
|---|---|
| 27. 데이터프레임 결합하기 (작성중) (0) | 2021.05.26 |
| 25. 데이터프레임 구조 변경하기 (작성중) (0) | 2021.05.23 |
| 24. 데이터프레임 탐색하기 (작성중) (0) | 2021.05.22 |