데이터 분석에 앞서, 원 데이터셋을 쉽게 관리하고자 취합(Mash-Up)할 필요가 있습니다. R에서 기본적으로 제공하는 rbind(), cbind(), merge() 함수를 이용하여 취합할 수 있습니다. 특히, merge 함수의 경우에는 SQL 쿼리의 join 문법과 비슷합니다.
25.1. 데이터셋의 물리적 행 결합, rbind()
데이터셋을 물리적으로 결합한다는 의미는 단순히 기워붙인다는 의미입니다. 물리적으로 결합하고자 할 때는 아래의 조건을 요구합니다.
①두 데이터셋의 구조가 동일해야함
②두 데이터셋의 적용하고자 하는 행(혹은 열)의 이름과 개수가 동일해야함
예시를 위해 이전 포스트인 <9. 데이터 구조 파악하기>의 데이터셋을 변형하여 1반, 2반 학생 데이터셋인 class_01_dataset, class_02_dataset을 정의하겠습니다.
class_01_dataset <- data.frame(name = c("PSH", "CGE", "CSH", "CMJ", "CJH"),
gender = factor(c("m", "f", "m", "f", "m")),
korean = c(35, 92.5, 70, 85, 60),
math = c(65L, 80L, 88L, 67L, 28L),
test_pass = c(FALSE, TRUE, TRUE, TRUE, FALSE))
class_02_dataset <- data.frame(name = c("LSS", "PBH", "KSB", "MSH", "JYJ"),
gender = factor(c("m", "m", "m", "m", "f")),
korean = c(80, 95, 86, 75, 60),
math = c(68L, 80L, 96L, 65L, 85L),
test_pass = c(FALSE, TRUE, TRUE, FALSE, FALSE))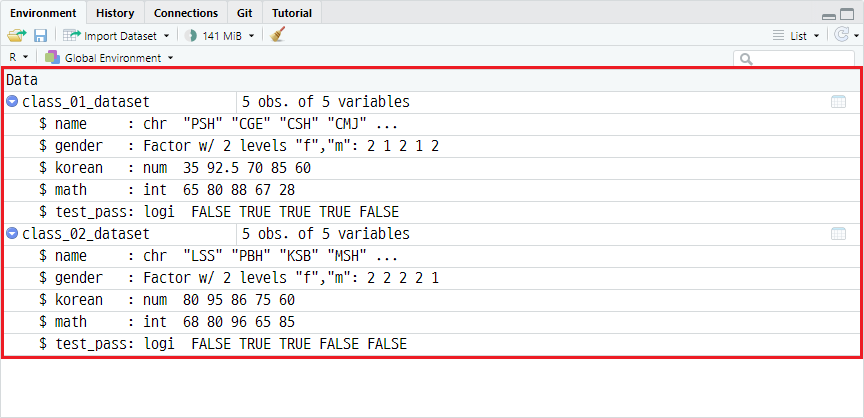
두 데이터셋을 행 기준으로 합치고자 한다면 다음의 과정을 행합니다.
student_dataset <- rbind(class_01_dataset, class_02_dataset)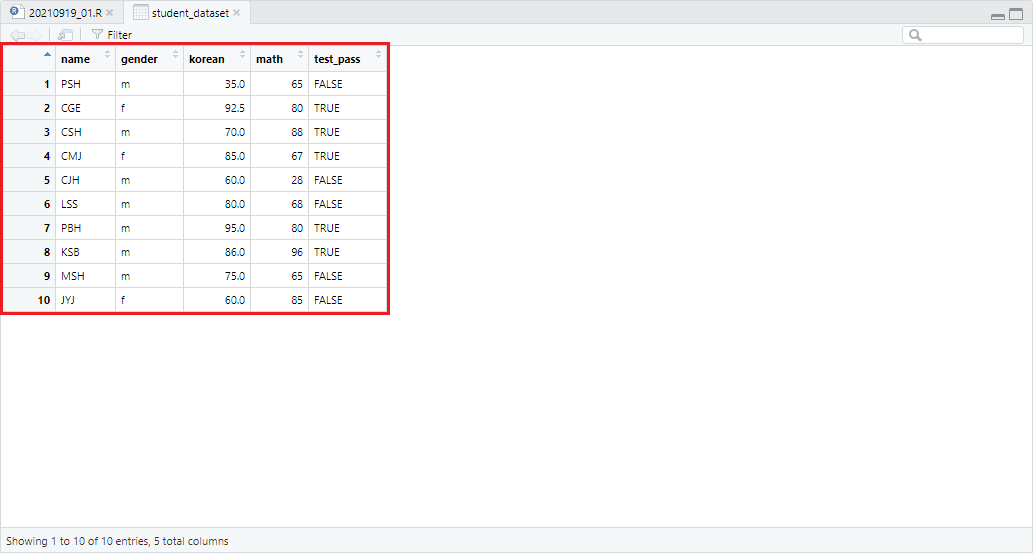
25.2. 데이터셋의 물리적 열 결합, cbind()
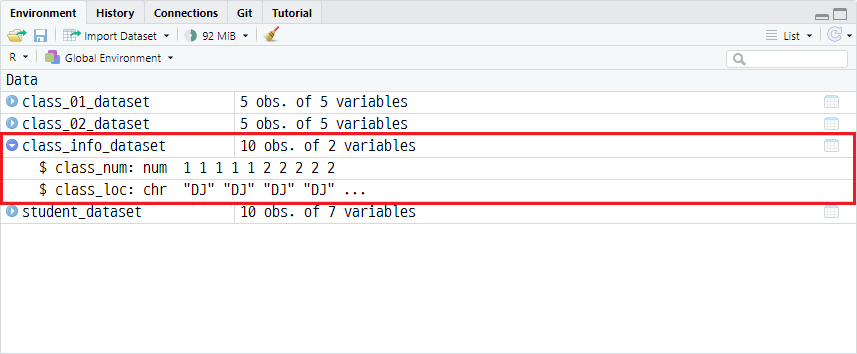
예시를 위해 추가적인 정보(학생의 반 번호, 반 위치)를 부여할 class_info_dataset을 정의하겠습니다.
class_info_dataset <- data.frame(
class_num = c(01, 01, 01, 01, 01, 02, 02, 02, 02, 02),
class_loc = c(rep("DJ", 5), rep("SU", 5))
)
student_dataset에 추가적인 정보(class_info_dataset)를 열로써 결합하고자 할 때는 다음과 같습니다.
student_dataset <- cbind(student_dataset, class_info_dataset)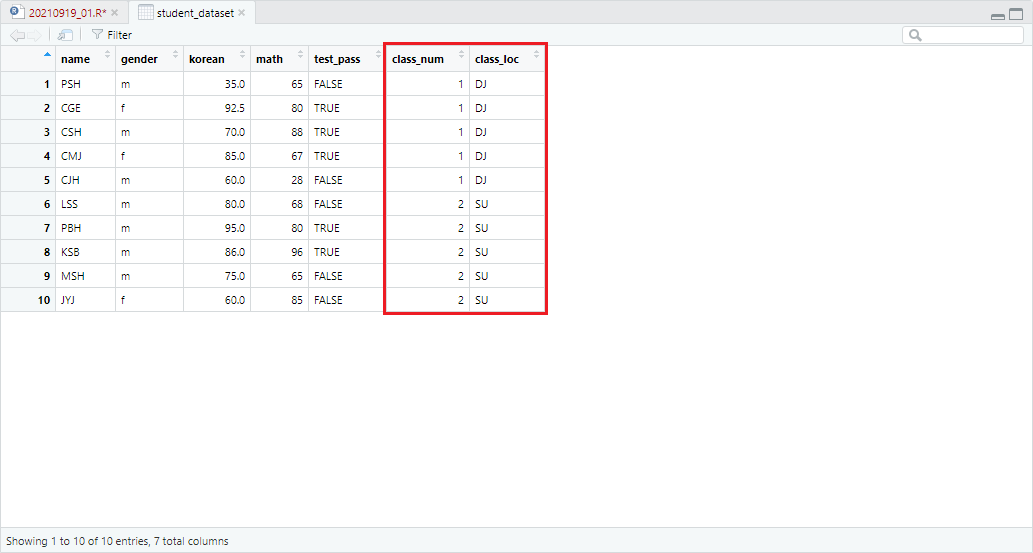
25.3. 데이터셋의 논리적 결합, merge()
(1) merge() 함수의 구조
merge() 함수는 데이터셋을 논리적으로 결합하는 함수입니다. 두 데이터셋의 기준이 되는 key 값을 바탕으로 결합하는데, 함수의 구조는 다음과 같습니다.
| merge(x, y, by, all, ... ) |
| 파라미터 | 설명 |
| x | 데이터셋 1 |
| y | 데이터셋 2 |
| by | 결합 기준이 되는 열 지정, 'by.x'∙'by.y' 파라미터로 대신 사용 가능 |
| all | 공통된 값이 없을 때 처리 기준 정의, False일 경우 제외, True일 경우 NA 처리 |
(2) all 파라미터가 TRUE인 경우
예시를 위해 학급의 직업 정보가 존재하는 job_info_dataset을 정의하면 다음과 같습니다. job 변수의 WK는 근로자(WorKer), ST는 학생(STudent)를 의미합니다.
job_info_dataset <- data.frame(name = c("PSH", "CGE", "CSH", "LSS", "KSB"),
job = c("WK", "ST", "ST", "ST", "WK"))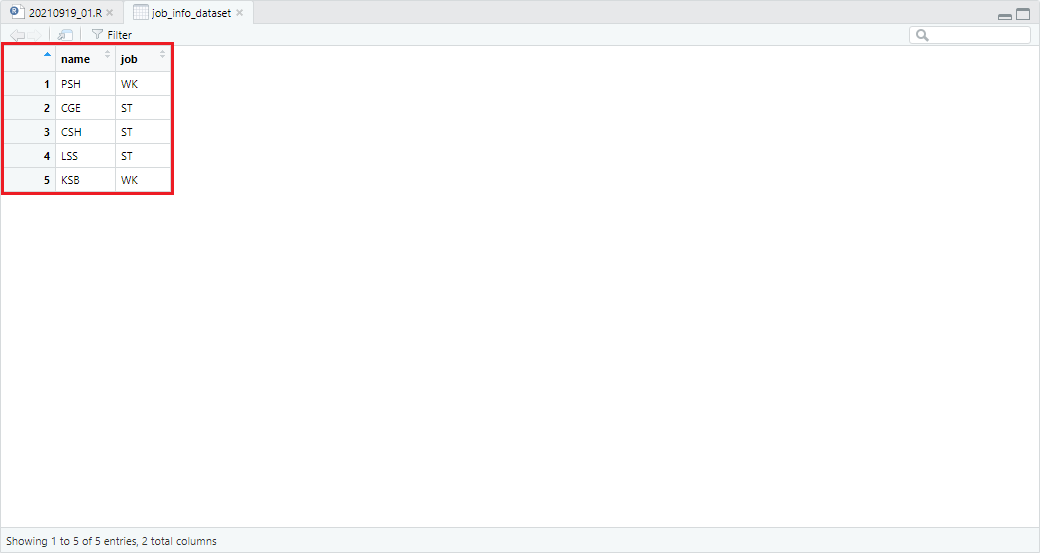
job_info_dataset과 student_dataset을 name 열을 기준으로 병합할 때 all 파라미터를 FALSE로 정의할 경우 다음과 같습니다.
student_dataset <- merge(student_dataset, job_info_dataset, by='name', all=TRUE)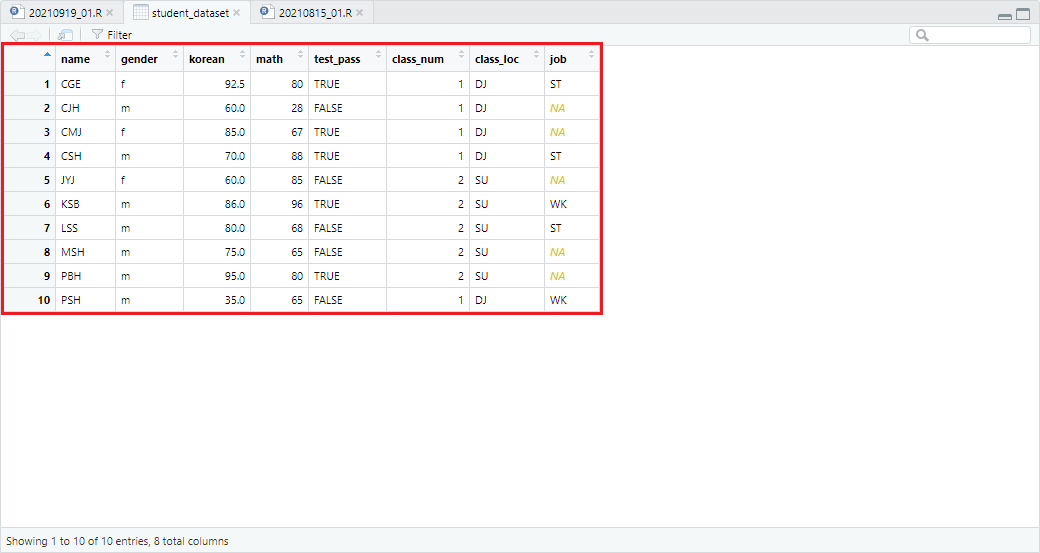
처리 결과 job_info_dataset에 명시되지 않은 학생들은 NA(결측치) 처리됨을 확인할 수 있습니다.
(3) all 파라미터가 FALSE인 경우
student_dataset을 다시 정의한 후, job_info_dataset을 함께 결합할 때 all 파라미터를 FALSE로 정의할 경우,
student_dataset <- merge(student_dataset, job_info_dataset, by="name", all=FALSE)
처리 결과를 살펴보면, job_info_dataset에서 명시된 학생들만 정의되고, 나머지 행들은 삭제됐음을 확인할 수 있습니다.
'Ⅱ. 데이터 전처리 > ⅰ. Base 문법' 카테고리의 다른 글
| 29. 중복값 파악 및 처리하기 (작성중) (0) | 2021.05.31 |
|---|---|
| 28. 결측값 생성, 파악 및 처리하기 (수정중) (0) | 2021.05.28 |
| 26. 데이터프레임 그룹핑하기 (작성중) (0) | 2021.05.24 |
| 25. 데이터프레임 구조 변경하기 (작성중) (0) | 2021.05.23 |