머신러닝의 특정 모델은 데이터셋의 각 컬럼의 측정 단위가 다를 경우, 패턴을 파악하는데 있어 잘못된 알고리즘(계산)을 수행할 수 있습니다. 이를 해결하는 방법을 피쳐 스케일링(Feature Scaling) 혹은 리스케일링(Rescaling)이라고 정의하며, 스케일링하는 방법은 크게 표준화(Standard Scaler) · 정규화(Normalization) · 로버스트 정규화(Robust Scaler)으로 구성되어 있습니다.
32.1. 스케일링(Scaling)의 정의와 활용
(1) 스케일링의 정의와 방법
스케일링이란 데이터셋의 수치형 컬럼의 값의 범위를 통일하는 작업, 즉 정규화를 의미합니다. 현업에서는 보통 표준화, 정규화라는 명칭은 헷갈릴 수 있다보니 스케일링이라는 용어를 많이 사용합니다. 일반적인 스케일링의 수식은 다음과 같습니다.
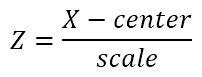
Z는 스케일링 후의 컬럼, X는 스케일링 전의 컬럼(원 자료)을 의미하며 center, scale 변수에 대한 값은 스케일링의 방법에 따라 다른데, 이는 아래 파트에서 설명하겠습니다.
(2) 스케일링 함수, scale()
R에서는 scale() 함수를 이용하여 데이터셋을 스케일링 처리할 수 있습니다. 함수의 형태는 다음과 같습니다.
| scale(x, center = TRUE, scale = TRUE) |
| 파라미터 형태 | 설명 |
| x | 숫자형 데이터프레임, 매트릭스, 벡터 |
| center | 원데이터의 차감 값, TRUE 시 해당 컬럼의 평균으로 지정 |
| scale | 원데이터의 차감 후 나눌 값, TRUE 시 해당 컬럼의 표준편차로 지정 |
(3) 예시
예를 들어 머신러닝용 연습 데이터셋인 Boston 데이터셋을 기준으로 ZN, TAX 컬럼 별 측정 단위의 차를 파악하면 다음과 같습니다. 해당 데이터셋에 대한 설명은 <Boston House Prices-Advanced Regression Techniques>에서 확인하세요.
boston_raw <- read.csv("Data/Boston.csv")
boston <- boston_raw[, c("ZN", "TAX")] #BACK-UP
View(boston)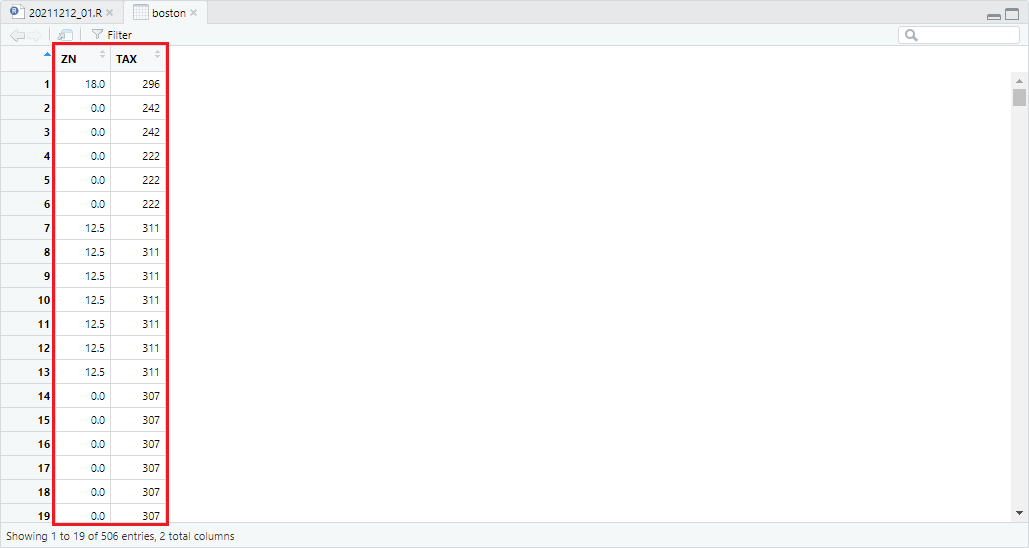
보시는 바와 같이 ZN 컬럼은 십(10)의 단위로 구성되어있고, TAX 컬럼은 백(100)의 단위로 구성되어 있음을 확인할 수 있습니다. 이를 해결하기 위해 scale() 함수를 사용하는 방법은 다음과 같습니다.
boston$ZN <- scale(boston$ZN)
boston$TAX <- scale(boston$TAX)
ZN, TAX 컬럼 모두 일(1)의 단위로 구성되어 있음을 확인할 수 있습니다.
32.2. 스케일링의 종류
(1) 표준화(Standardization; Standard Scaling)
표준화는 마치 정규분포의 표준화처럼, 원 데이터에 평균을 빼고 표준편차를 나누어 스케일링 처리하는 방법입니다. 보통 스탠다드 스케일링(Standard Scaling)처리한다고 표현합니다. 일반적으로 해당 컬럼의 분포가 정규분포(Normal Distribution)를 따른다고 가정했을 때(혹은 그러한 경우) 사용하기 좋습니다.

scale() 함수에서 center, scale 파라미터를 생략한다면 기본적으로 스탠다드 스케일링 처리되며, 이는 수식으로 다음과 같습니다. 허나 명시한다면 center 파라미터에 mean() 함수를, scale 파라미터에 sd() 함수를 대입하여 사용합니다. 기존의 boston 데이터셋을 이용하여 처리하는 예시는 다음과 같습니다.
boston <- boston_raw[, c("ZN", "TAX")] #BACK-UP
boston$ZN <- scale(boston$ZN, center=mean(boston$ZN), scale=sd(boston$ZN))
boston$TAX <- scale(boston$TAX, center=mean(boston$TAX), scale=sd(boston$TAX))처리 결과를 살펴봤을 때 center, scale 파라미터를 생략했을 때와 결과가 동일합니다.
(2) 정규화(Normalization; Min-Max Scaling)
정규화는 가장 작은 값을 0으로, 가장 큰 값을 1로 처리하여 해당 컬럼의 범위를 0과 1사이로 변환하는 방법입니다. 정규화란 표현보다는 주로 민맥스 스케일링(Min-Max scaling)이라 표현하며, 일반적으로 해당 컬럼이 정규분포가 아니거나 음수를 취하면 안될 경우에 사용합니다. 수식으로는 다음과 같습니다.
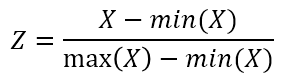
scale() 함수에서 center 파라미터에 min() 함수를, scale 파라미터에 (max()-min()) 함수를 대입하여 민맥스 스케일링으로 처리할 수 있는데, 예시는 다음과 같습니다.
boston <- boston_raw[, c('ZN', 'TAX')] #BACK-UP
boston$ZN <- scale(boston$ZN, center=min(boston$ZN), scale=(max(boston$ZN)-min(boston$ZN)))
boston$TAX <- scale(boston$TAX, center=min(boston$TAX), scale=(max(boston$TAX)-min(boston$TAX)))
summary(boston)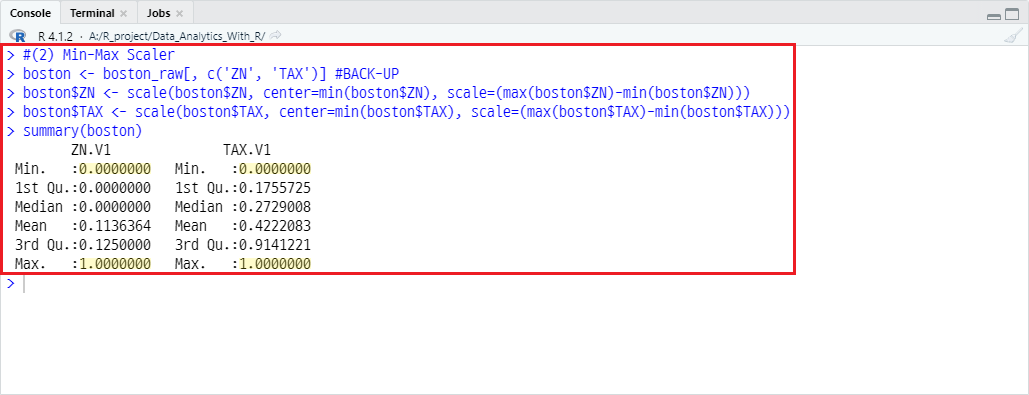
Summary() 함수를 통해 처리 결과를 파악해 봤을 때, 각 컬럼 별 최소, 최대값이 0과 1로 지정됐음을 확인할 수 있습니다.
(3) 로버스트 정규화(Robust Normalization; Robust Scaler)
표준화와 정규화는 이상치에 취약하단 단점이 있습니다. 특히 정규화는 이상치에 더욱 민감한데, 이러한 이상치에 강건하게 대처하기 위한 방법으로 로버스트 정규화를 이용할 수 있습니다. 로버스트 정규화는 컬럼의 중앙값이 0, IQR이 1으로 변환하는 방법이며, 수식은 다음과 같습니다.

Q1, Q2, Q3는 컬럼의 분포 중 하위 25%, 50%, 75%를 의미합니다. scale() 함수에서 center 파라미터에는 median() 함수를, scale 파라미터에 IQR() 함수를 이용하여 로버스트 스케일링 처리할 수 있습니다. boston 데이터셋을 이용한 예시는 아래와 같습니다.
boston <- boston_raw[, c("ZN", "TAX")] #BACK-UP
boston$ZN <- scale(boston$ZN, center=median(boston$ZN), scale=IQR(boston$ZN))
boston$TAX <- scale(boston$TAX, center=median(boston$TAX), scale=IQR(boston$TAX))
summary(boston)
Summary() 함수를 통해 처리 결과를 파악해 봤을 때, 각 컬럼의 중앙값(Q2)이 0, IQR이 1임을 확인할 수 있습니다.
(4) 로그 정규화,
(냐냐냐내용작성중)
'Ⅱ. 데이터 전처리 > ⅰ. Base 문법' 카테고리의 다른 글
| 32. 텍스트 데이터 전처리하기 (작성중) (0) | 2021.06.11 |
|---|---|
| 31. 시계열 데이터 전처리하기 (수정중) (0) | 2021.06.08 |
| 30. 이상치 판단 및 전처리하기 (수정중) (0) | 2021.06.01 |
| 29. 중복값 파악 및 처리하기 (작성중) (0) | 2021.05.31 |