우리는 정제 및 분석과정에서 데이터셋의 일부만 사용하고자 할 때가 있습니다. 이를 부분 선택(subsetting)이라고 정의하는데 부분 선택하는 방법은 크게 인덱싱, 슬라이싱, 필터링으로 구분됩니다. 인덱싱의 경우 데이터 구조의 원소 위치(첨자; index)를 통해 선택하는 방법을 의미합니다. 인덱싱은 [], [[]], $ 키워드를 통해 처리할 수 있습니다.
11.1. 벡터 인덱싱
(1) 벡터 인덱싱, [{idx}]
벡터에서 인덱싱은 벡터의 원소 위치를 통해 부분 선택할 수 있습니다. 인덱싱의 문법 구조는 다음과 같습니다.
| vector_name[idx] |
(2) 예시
예시를 위해 vector_01 객체를 생성하고, 3번째 원소를 인덱싱한다면 다음과 같습니다.
vector_01 <- c(1, 2, 3, 4, 5)
vector_01
vector_01[3]
(3) 특정 원소를 제외하고 인덱싱, [-{idx}]
반대로 벡터의 특정 원소를 제외하고 모두 출력하고자 한다면, -을 이용할 수 있습니다. vector_01 객체에서 3번 째 원소를 제외하여 부분 선택하는 예시는 다음과 같습니다.
vector_01[-3]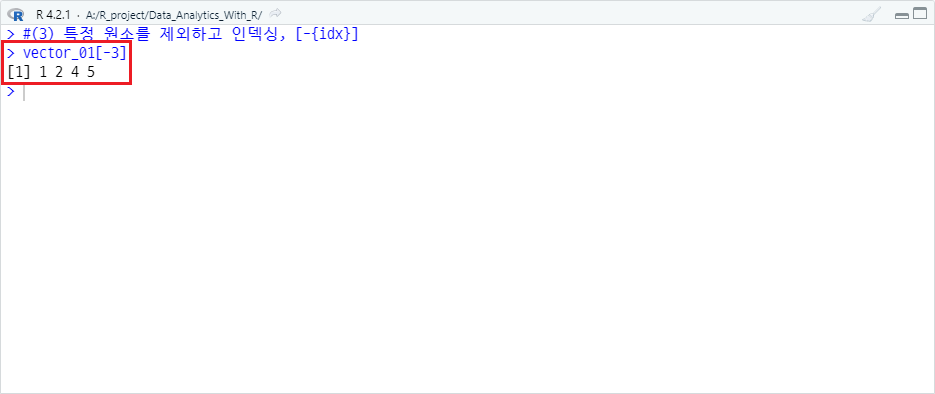
(4) 여러 원소 인덱싱, [c({idx_01}, {idx_02}, ⋅⋅⋅)]
여러 원소를 부분 출력하고자 한다면 ,을 이용할 수 있습니다. vector_01 객체에서 1, 5, 3번 째 원소를 출력하고자 한다면 다음과 같습니다.
vector_01[c(1, 5, 3)]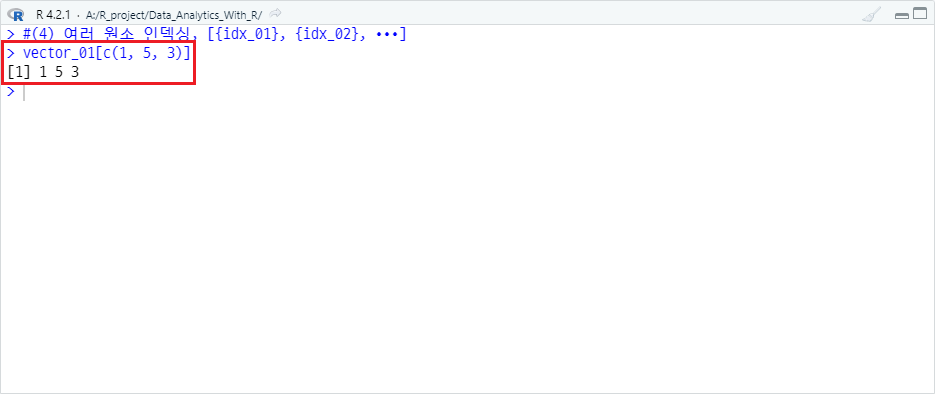
11.2. 행렬 인덱싱
(1) 행렬 인덱싱, [{row_idx}, {col_idx}]
행렬 인덱싱은 ,을 통해 행 인덱스와 열 인덱스를 구분합니다. 문법 구조는 다음과 같습니다.
| matrix_name[row_idx, col_idx] |
(2) 예시
예시를 위해 3×3 행렬로 구성된 matrix_01 객체를 정의하고, 3행 2열을 인덱싱하면 다음과 같습니다.
matrix_01 <- matrix(data=c(1, 2, 3, 4, 5, 6, 7, 8, 9),
nrow=3,
byrow=TRUE)
matrix_01
matrix_01[3, 2]
11.3. 배열 인덱싱
(1) 배열 인덱싱, [{dim1_idx}, {dim2_idx}, {dim3_idx}, ⋅⋅⋅]
R의 배열 구조는 행렬 형식에서 차원을 추가로 확장한 개념인데, 문법 상 dim1, dim2는 행열 축을 의미하고 나머지 축을 통해 차원을 확장하여 적재합니다. 배열 인덱싱의 문법은 다음과 같습니다.
| array_name[dim1_idx, dim2_idx, dim3_idx, ⋅⋅⋅] |
(2) 예시
2개의 층과 3×3 행렬으로 구성된 array_01 객체를 정의하고, 1행 3열 2층의 원소를 인덱싱하면 다음과 같습니다.
array_01 <- array(
data=c(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18),
dim=c(3, 3, 2)
)
array_01
array_01[1, 3, 2]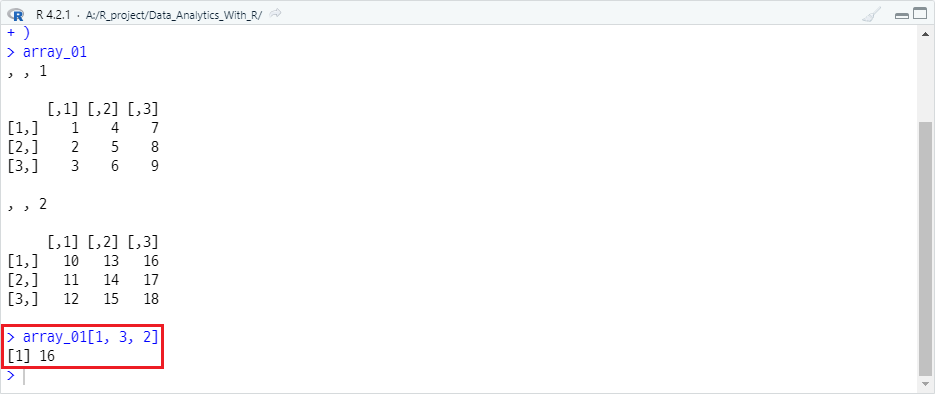
PLUS) 배열 원소 인덱싱, [{element_idx}]
배열 구조에서 축 구분(,) 없이 인덱싱할 경우, 입력된 데이터(원소)의 인덱스를 기반으로 부분 선택됩니다. 예를 들어 array_01 객체의 13번째 원소를 인덱싱할 경우 다음과 같습니다.
array_01[13]
11.4. 데이터프레임 인덱싱
(1) 데이터프레임 인덱싱, [{row_idx_number}, {col_idx_number}]
데이터프레임 인덱싱은 행렬과 동일한 문법을 가집니다. 데이터 프레임의 인덱싱 방법은 다음과 같습니다.
| dataframe_name[row_idx, column_idx] |
(2) 예시
이전 포스트인 <10. 데이터 구조 파악하기>를 참고해 student_df 객체을 생성하고, PSH의 수학점수(1행 4열)을 인덱싱하면 다음과 같습니다.
student_df <- data.frame(
name = c("PSH", "CGE", "CSH", "CMJ", "CJH"),
gender = factor(c("m", "f", "m", "f", "m")),
korean = c(35, 92.5, 70,85, 60),
math = c(65L, 80L, 88L, 67L, 28L),
test_pass = c(FALSE, TRUE, TRUE, TRUE, FALSE)
)
student_df
student_df[1, 4]
11.5. 데이터프레임 컬럼 인덱싱
(1) 데이터프레임 컬럼 인덱싱, [{col_idx}]
데이터프레임에서 행열 구분(,) 없이 부분 선택할 경우, 해당 컬럼 값을 데이터프레임 구조로 반환합니다.
| dataframe_name[column_idx] |
예를 들어 student_df 객체에서 2번째 컬럼값을 부분 선택하고자할 경우, 다음과 같습니다.
student_df[2]
(2) 데이터프레임 컬럼 인덱싱, [[{col_idx}]]
[[]]을 통해 인덱싱할경우, 데이터프레임 구조가 아닌 벡터 구조로 값을 반환합니다. 문법 구조는 다음과 같습니다.
| dataframe_name[[column_idx]] |
동일한 예시를 들어 student_df 객체에서 2번째 컬럼을 부분 선택할 경우, 결과는 다음과 같습니다.
student_df[[2]]
(4) 데이터프레임 컬럼 인덱싱, ${col_name}
데이터프레임에서는 $을 통해 컬럼을 부분 선택하여 벡터로 반환할 수 있습니다. 문법의 구조는 다음과 같습니다.
| dataframe_name$column_name |
예를 들어 math 컬럼의 모든 값을 출력하고자 하는 경우 코드는 다음과 같습니다.
student_df$math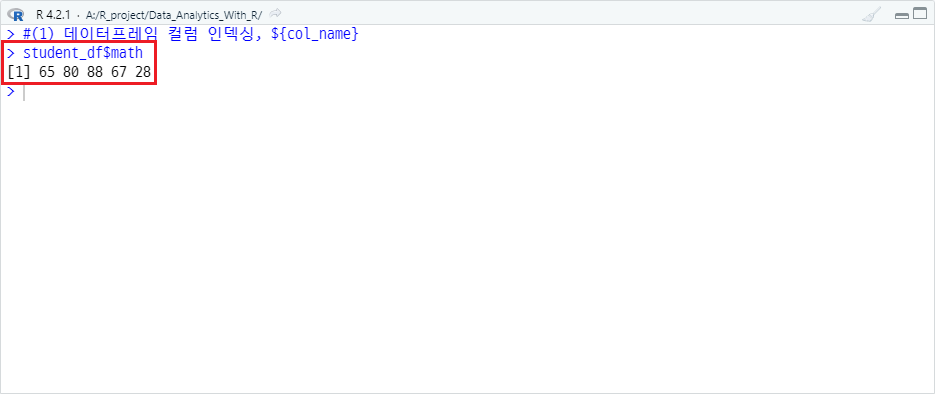
PLUS) 컬럼명 인덱싱
데이터 프레임에서는 인덱스 대신 컬럼명을 통해서도 부분 선택할 수 있습니다. 이는 데이터프레임뿐만 아니라 컬럼명이 부여된 객체 모두 가능합니다. 이전 예시에서 컬럼 이름을 통해 부분 선택할 경우 다음과 같습니다.
student_df[1, "math"]
student_df["gender"]
student_df[["gender"]]
11.6. 리스트 인덱싱
(1) 리스트 인덱싱, [[{object_idx}]]
리스트는 리스트에 저장된 객체를 부분 선택하는 구조로 되어 있습니다. 리스트 인덱싱의 문법은 다음과 같습니다.
| list_name[object_idx] |
(2) 예시
해당 포스트에서 정의된 vector_01, matrix_01, array_01, student_df 객체를 저장하는 list_01 객체를 정의하고 2번 째 객체(matrix_01)를 부분 선택하면 다음과 같습니다.
list_01 <- list(
vector_01 = vector_01,
matrix_01 = matrix_01,
array_01 = array_01,
student_df = student_df
)
list_01
list_01[[2]]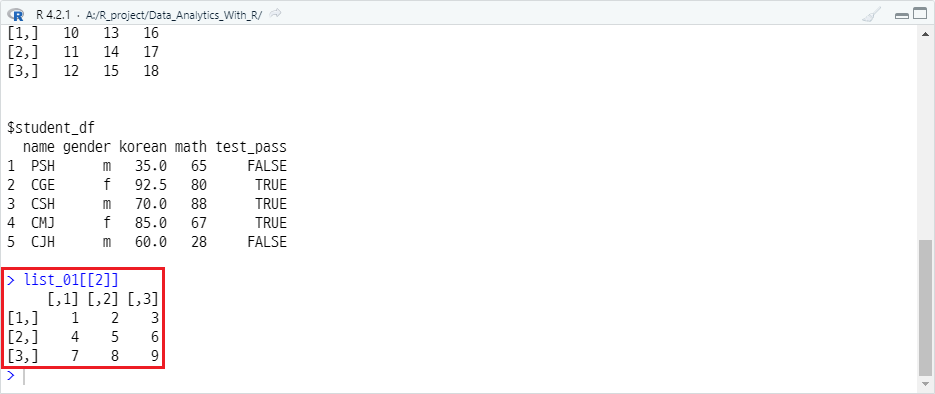
PLUS) 중첩 인덱싱
모든 객체에서는 연속적으로 부분 선택이 가능한데, 예를 들어 list_01 객체 내부에 있는 matrix_01 객체에서도 부분 선택을 수행하고자 할 경우 다음과 같습니다.
list_01[[2]][3, 2]
'Ⅰ. R 기초' 카테고리의 다른 글
| 13. 데이터 구조 별 필터링하기 (0) | 2020.10.07 |
|---|---|
| 12. 데이터 구조 별 슬라이싱하기 (0) | 2020.10.01 |
| 10. 데이터 구조 파악하기 (0) | 2020.09.28 |
| 9. 데이터 유형 파악하기 (0) | 2020.09.25 |