데이터 입력은 데이터 분석을 위한 첫 단계입니다. 데이터 입력은 크게 두 가지 방법이 있는데, 하나는 직접 데이터 구조와 형식을 정의하고 입력하는 것이고 나머지 하나는 외부 데이터 파일을 R로 불러오는 것입니다. 외부에서 데이터를 불러올 경우 read.*() 함수를 사용하며, 확장자명에 따라 함수명과 일반 파라미터가 상이합니다.
20.1. 데이터셋 불러오기, read.table()
(1) read.table() 함수의 구조와 파라미터
테이블이란 특정 데이터를 행과 열로 구조화한 표입니다. read.table() 함수는 csv, txt 등 데이터를 불러올 수 있으나 해당 확장자 양식에 맞게 여러 파라미터들을 재할당해야 하므로 확장자에 최적화된 함수를 사용하는 것이 좋습니다. 함수의 구조는 다음과 같습니다.
| read.table(file, header, sep, quote, dec, numerals, row.names, col.names, as.is, ∙∙∙ ) |
| 파라미터 형태 | 설명 |
| file | 파일 경로 지정, 작업파일에 위치할 경우 "파일이름"으로 지정 |
| header = FALSE | TRUE면 첫 행을 필드명으로 인식, FALSE면 첫 행을 필드명 미인식 |
| sep = "" | 구분자 지정, ""로 설정할 경우 공백으로 인식 |
| quote = "\"'" | 인용문 지정, 기본값은 "(double quotation marks) |
| dec = "." | 소수점 인식을 위해 해당 파일에서 사용한 문자(기호) 설정 |
| numerals=c("allow.loss", "warn.loss", "no.loss") | 소수점 정밀도(precision) 변환 문제에 따른 설정 지정 |
| row.names | 행 이름을 사용할지 지정 |
| col.names | 열 이름을 사용할지 지정 |
| na.strings = "NA" | 결측값의 표기명 설정, 기본값으로 "NA" 지정됨 |
| nrows = -1 | 몇 행까지 데이터를 불러올지 결정, 음수일경우 무시 |
| skip = 0 | 1행부터 몇행까지 생략할지 결정 |
| check.names = TRUE | TRUE면 열이름이 적합하지 않을 경우, make.name() 함수에 의거해 정정 |
| fill = !blank.lines.skip | TRUE면 비어있는 원소(결손값)이 있을 경우 "NA"처리, FALSE면 오류 반환 |
| strip.white = FALSE | TRUE면 값에 선행 후행에 있는 띄어쓰기를 삭제 |
| blank.lines.skip = TRUE | TRUE면 비어있는 행이 있을 경우 생략, FALSE면 "NA" 처리 |
| comment.char = "#" | 주석기호 설정 |
| stringsAsFactors = default.stringsAsFactors() | TRUE면 문자형 벡터를 팩터화, FALSE면 문자화 |
| encoding = "unknown" | 인코딩방법 선택, 일반적으로 "UTF-8"로 지정 |
(2) 예시
보통 대부분의 데이터셋은 csv형식이지만, 부득이하게 필드 구분을 ,로 하지 못할 경우 tsv 파일을 사용할 때가 있습니다. 그럴 때 read.table() 함수를 사용하는데, 예를 들어 학생 5명의 소득과 자산 현황을 기록한 tsv 파일을 불러오겠습니다. 예제 파일은 아래에 링크돼있습니다.
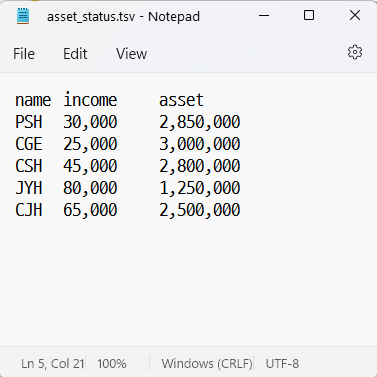
해당 파일을 다운로드를 하고, 작업 폴더에 위치시킨 후 R로 데이터를 불러오는 코드는 다음과 같습니다.
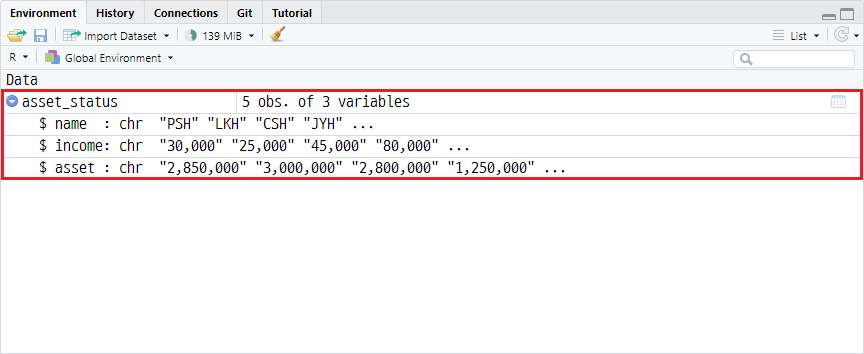
asset_status <- read.table("asset_status.tsv",
sep="\t",
header=TRUE)환경창에서 결과를 확인하면 다음과 같이 데이터프레임 객체가 할당됐음을 확인할 수 있습니다.
20.2. csv 형식 데이터셋 불러오기, read.csv()
(1) read.csv() 함수의 구조와 파라미터
csv(comma-separated values) 파일이란 테이블(데이터셋)의 필드를 ,로 구분한 텍스트 파일입니다. csv 확장명을 사용하며 함수의 구조는 다음과 같습니다.
| read.csv(file, header = TRUE, sep = ",", quote = "\"", dec = ".", fill = TRUE, ∙∙∙ ) |
read.csv() 함수의 파라미터들은 read.table() 함수와 대부분 동일하나 기본값 설정이 다르므로 주의해야합니다. 주로 header, sep, stringsAsFactors, na.strings 파라미터를 사용해 데이터셋을 불러옵니다.
(2) 예시
예시를 위해 이전 포스트인 <9. 데이터 구조 파악하기>를 참고해 student_dataset을 csv파일로 정의하면 다음과 같습니다. 예제 파일은 아래에 링크되어 있습니다.
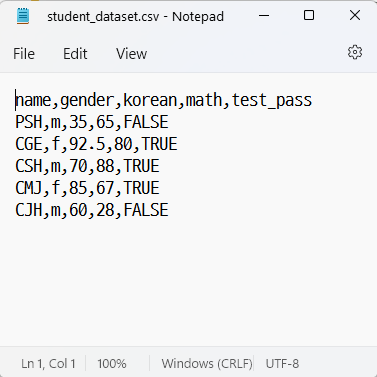
해당 파일을 다운로드를 하고, 작업 폴더에 위치시킨 후(아니라면 경로를 지정한 뒤) R로 데이터를 불러오는 코드는 다음과 같습니다. 아래의 경우는 student_dataset 파일을 data 폴더에 위치시킨 경우의 코드입니다.
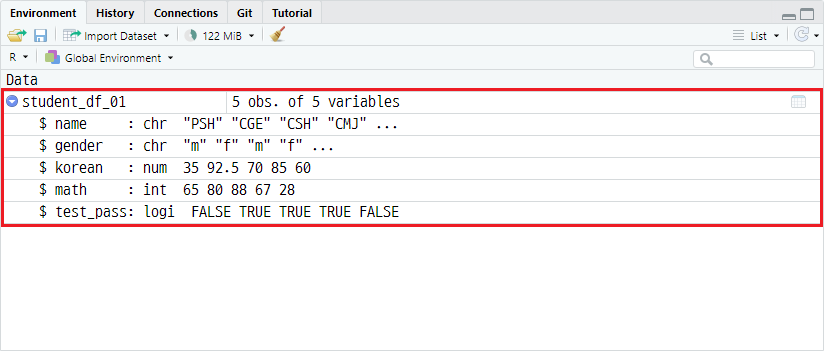
student_df_01 <- read.csv(file="data/student_dataset.csv",
header=TRUE)환경창에서 결과를 확인하면 다음과 같이 데이터프레임 객체가 할당됐음을 확인할 수 있습니다.
20.3. xlsx 형식 데이터셋 불러오기, read_xlsx()
(1) readxl 패키지 설치 및 활성화
excel의 확장자명인 .xls(x)파일을 불러올 때는 readxl 패키지를 사용합니다. readxl 패키지는 Other Packages에 속해있으므로 패키지를 설치하고 활성화해야합니다. 해당 코드는 다음과 같습니다.
install.packages("readxl")
library(readxl)
(2) read_xlsxcsv() 함수의 구조와 파라미터
xls(x)파일을 불러오기 위해선 read_xlsxcsv() 함수를 사용하며, 그 구조는 다음과 같습니다.
| read_xlsx(path, sheet, range, col_names, col_types, na, trim_ws, skip, n_max, ∙∙∙ ) |
| 파라미터 형태 | 설명 |
| path | 파일 경로 지정 |
| sheet = NULL | 파일의 sheet 지정, sheet num이나 name 지정 가능 |
| range = NULL | 읽을 셀의 범위를 지정, 예를 들어 "B2:D57"로 지정 가능 |
| col_names = TRUE | 열 이름을 사용할지 결정 |
| na = "" | 결측치로 처리할 문자열 지정, 기본값은 "" |
| skip = 0 | 1행부터 몇행까지 생략할지를 결정 |
| n_max = Inf | 몇 행까지 데이터를 불러올지 결정 |
(3) 예시
위에서 예시로 들었던 student_dataset.csv 파일을 student_dataset.xlsx 파일로 변환하여 불러오겠습니다. 예제 파일은 아래에 링크돼있습니다.
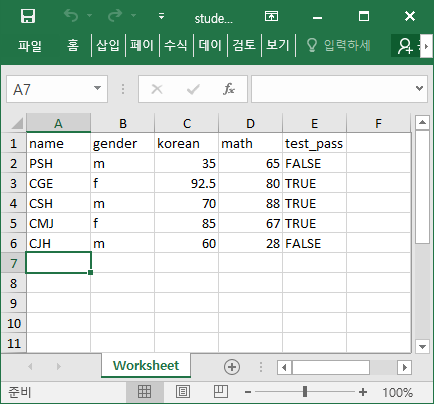
해당 파일을 다운로드를 하고, 작업 폴더에 위치시킨 후(아니라면 경로를 지정한 뒤) R로 데이터를 불러오는 코드는 다음과 같습니다.
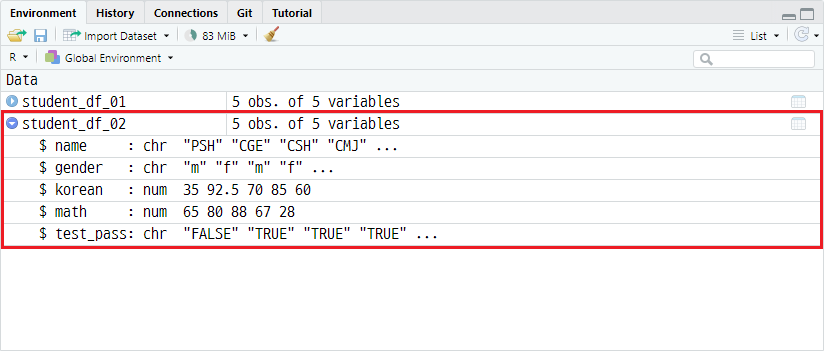
student_df_02 <- read_xlsx(path="data/student_dataset.xlsx",
sheet=1,
col_names=TRUE)환경창에서 결과를 확인하면 다음과 같이 객체가 할당됐음을 확인할 수 있습니다.
'Ⅰ. R 기초' 카테고리의 다른 글
| 22. 제어문 파악하기 (0) | 2021.05.20 |
|---|---|
| 21. 내부 데이터 저장하기 (수정중) (0) | 2021.05.18 |
| 19. 선형대수 연산 시행하기 (수정중) (0) | 2021.05.14 |
| 18. 기본 산술 함수 파악하기 (0) | 2020.10.27 |